使用Neon优化移动设备上的C语言性能
Yourtion 创作于:2014-09-29
全文约 3364 字,
预计阅读时间为 10 分钟
这是很久前就像写的文章,大概一个月了吧,各种忙碌与偷懒,现在终于开始写下来。前段时间主要在做一个C语言程序的移动平台移植,因为设计到性能问题,所以大概看了一下Neon技术。
ARM® NEON™ 通用 SIMD 引擎可有效处理当前和将来的多媒体格式,从而改善用户体验。 NEON 技术可加速多媒体和信号处理算法(如视频编码/解码、2D/3D 图形、游戏、音频和语音处理、图像处理技术、电话和声音合成),其性能至少为 ARMv5 性能的 3 倍,为 ARMv6 SIMD 性能的 2 倍。
详细介绍可以看:http://www.arm.com/zh/products/processors/technologies/neon.php
先贴一下我用来测试的两个简单Demo吧。
第一个是使用已经iOS或者Android已经封装的Neon实现(参考:http://www.verydemo.com/demo_c92_i387648.html):
C语言实现:
static float calc_c(const float* data, int size)
{
float sum = 0.f;
for (int i = 0; i < size; ++i) {
sum += data[i];
}
return sum;
}
Neon的实现(需要引入Neon #include <arm_neon.h>):
static float calc_neon(const float* data, int size)
{
float sum = 0.f;
float32x4_t sum_vec = vdupq_n_f32(0);
for (int i = 0; i < size / 4; ++i) {
float32x4_t tmp_vec = vld1q_f32 (data + 4*i);
sum_vec = vaddq_f32(sum_vec, tmp_vec);
}
sum += vgetq_lane_f32(sum_vec, 0);
sum += vgetq_lane_f32(sum_vec, 1);
sum += vgetq_lane_f32(sum_vec, 2);
sum += vgetq_lane_f32(sum_vec, 3);
int odd = size & 3;
if(odd) {
for(int i = size - odd; i < size; ++i) {
sum += data[i];
}
}
return sum;
}
第二个是使用Neon的汇编代码实现除2运算(参考:http://blog.noctua-software.com/arm-asm.html)
C语言实现:
static void div_by_2c(int16_t *x, int n)
{
int i;
for (i = 0; i < n; i++)
x[i] /= 2;
}
Neon加汇编(ARM assembly)实现:
static void div_by_2neon(int16_t *x, int n)
{
asm volatile (
"Lloop: \n\t"
"vld1.16 {q0}, [%[x]:128] \n\t"
"vshr.s16 q0, q0, #1 \n\t"
"vst1.16 {q0}, [%[x]:128]! \n\t"
"sub %[n], #8 \n\t"
"cmp %[n], #0 \n\t"
"bne Lloop \n\t"
// output
: [x]"+r"(x), [n]"+r"(n)
:
// clobbered registers
: "q0", "memory"
);
}
测试程序代码如下:
-(void)test
{
int c= 1000000;
float* d = malloc(sizeof(float)*c);
for (int i = 0; i<c; i++) {
d[i] = 1.0111f;
}
NSDate* tmpStartData = [NSDate date];
for (int t = 0; t<100; t++) {
calc_neon(d, c);
}
double deltaTime = [[NSDate date] timeIntervalSinceDate:tmpStartData];
NSLog(@"calc_neon cost time = %f ms", deltaTime*1000);
NSDate* tmpStartData1 = [NSDate date];
for (int t = 0; t<100; t++) {
calc_c(d, c);
}
double deltaTime1 = [[NSDate date] timeIntervalSinceDate:tmpStartData1];
NSLog(@"calc_c cost time = %f ms", deltaTime1*1000);
int n = 1024000;
int16_t* x= malloc(sizeof(int16_t)*n);
NSDate* tmpStartData2 = [NSDate date];
for (int t = 0; t<100; t++) {
div_by_2c(x,n);
}
double deltaTime2 = [[NSDate date] timeIntervalSinceDate:tmpStartData2];
NSLog(@"div_by_2c cost time = %f ms", deltaTime2*1000);
int16_t* x1= malloc(sizeof(int16_t)*n);
NSDate* tmpStartData3 = [NSDate date];
for (int t = 0; t<100; t++) {
div_by_2neon(x1,n);
}
double deltaTime3 = [[NSDate date] timeIntervalSinceDate:tmpStartData3];
NSLog(@"div_by_2neon cost time = %f ms", deltaTime3*1000);
}
执行速度对比(测试环境为iPhone5 iOS 8.0.2 Xcode6):
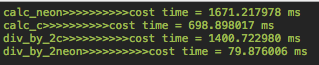
从测试效果上看,在iPhone5上可以提升1.3倍和16.5倍性能,当然这个只是一个简单的测试应用,具体实现和实践中的效果只有运用到算法中才能体现。
原文链接:https://blog.yourtion.com/use-neon-optimize-clang-example.html